Bonjour à tous,
Tout d’abord, non je ne suis pas mort ! 🙂 C’est juste que je n’ai trop pris le temps c’est dernier temps pour écrire. Mais je me rattrape avec cet article sur les routes sous angular7.
Continuer la lectureBonjour à tous,
Tout d’abord, non je ne suis pas mort ! 🙂 C’est juste que je n’ai trop pris le temps c’est dernier temps pour écrire. Mais je me rattrape avec cet article sur les routes sous angular7.
Continuer la lectureCoucou à tous,
Je vous avais parlé ici du site Carburmalin, que j’ai fait.
Pour rappel, le site vous affiche une prévision de l’évolution du prix des carburants pour les 4 prochains jours.
Je me suis dis que ça pouvait vous intéresser de savoir que j’ai fait une application du même nom sur le play store. Vous pouvez la trouver ici.
Si vous avez des remarques ou des avis n’hésitez pas à me les envoyer ou de les laisser sur le store.
Bonjour
Ça fait longtemps que je n’avais pas écris sur le blog. Aujourd’hui, je voudrais vous parler d’un projet perso : CarburMalin.
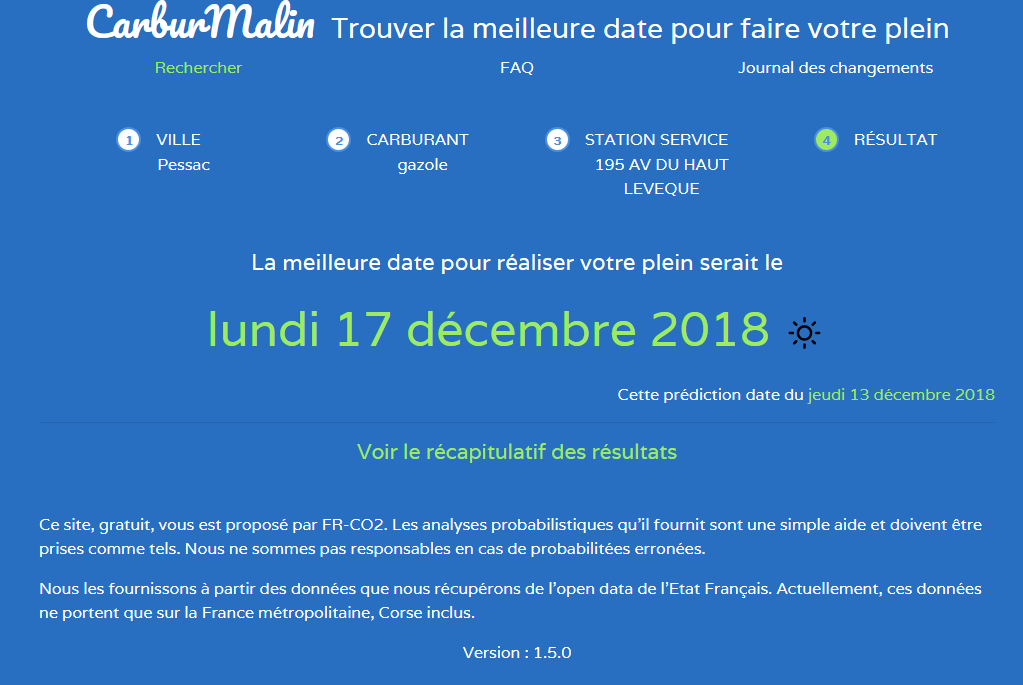
Site de prévision d’évolution du prix du carburant
Comme il s’agit d’IA, ça se base sur des modèles mathématiques et donc l’erreur est toujours possible. Mais je fais des vérifications sur les prédictions passées et ce matin le taux de réussite était de 89%.
Et petit plus de ce site, il est gratuit !
N’hésitez pas à y faire un tour et à me dire ce que vous en pensez !
Edit du 12 décembre 2018 : CarburMalin est sur android et vous pouvez trouver l’article sur le sujet ici.
Bonjour,
Comme je vous disais dans l’article sur Hateoas, je vais maintenant vous parler de l’architecture micro-services. Nous verrons les points communs et les différences avec les autres types d’architecture.
L’architecture micro-service se base sur MVC (pour Model View Controller ou en français : Modèle Vue Contrôleur).
Sur ce point, pas de révolution, votre application aura toujours une partie pour l’accès aux données (Modèle), une partie qui sera le point d’entrée de votre application (Contrôleur) et la partie pages web (Vue).
Comme toute architecture, elle n’est pas liée à un langage particulier mais représente une façon de faire applicable à tout type de langage (sauf exception).
Première différence, le contrôleur n’est pas un contrôleur web standard mais le plus souvent un contrôleur REST (basé sur les webservices de type REST).
Ca permet de renvoyer des pages html entières ou directement des flux json à la vue.
Deuxième différence, et la plus importante à mon avis, la responsabilité des contrôleurs.
Chaque contrôleur doit avoir une et une seule responsabilité. C’est-à-dire, gérer un seul type d’objet que ce soit pour la création, modification, affichage ou suppression. Et chaque fonction du contrôleur ne doit faire qu’une seule chose (l’ajout par exemple).
Si lorsque vous ajoutez un nouveau produit, vous souhaitez avoir la liste mise à jour, vous devrez faire deux appels au serveur. Le premier appel permettra l’ajout du nouveau produit et lorsque le retour est « Création OK », alors vous faites le deuxième appel au serveur qui lui servira à renvoyer la liste de tous les produits.
Si vous avez lu l’article précédent sur Hateoas, vous voyez l’intérêt de coupler ces deux notions. Ainsi le niveau de maturité 3 que représente Hateoas vous permettra de communiquer plus en détail avec le serveur et ainsi pouvoir découper vos actions de façon minimaliste.
Souvent avec les micro-services, les gens ne savent pas bien découper le travail et mélange les différentes actions dans une même fonction d’un même contrôleur. L’inconvénient est que la maintenance et les évolutions seront plus chères car plus compliquées.
En découpant de façon minimaliste la responsabilité d’une fonction (ce qu’elle doit faire), vous diminuez sa complexité et donc le cout de sa maintenance.
Imaginons que vous avez une fonction qui renvoie tous les produits et les sous-catégories, car vous n’avez pas respecté les micro-services. Maintenant il faut que vous ne renvoyez plus les sous-catégories car le client ne les veux plus dans cette page. Vous devez modifier plusieurs parties de votre fonction, ce qui augmente le risque de régression et d’impacts sur d’autres pages.
Dans le cas des micro-services, vous n’avez juste qu’à supprimer l’appel aux sous-catégories dans le javascript. Le risque de régression étant quasiment nul et la complexité pareil (sauf si votre JS est mal codé 🙂 ).
Troisième point, votre architecture coté serveur ressemble à vos urls.
C’est-à-dire que si vous avez store/product/ dans votre url, vos packages cotés serveurs auront la même architecture.
Cette logique est identique coté javascript si vous utilisez un framework du type angular.
L’avantage est que même sans connaitre l’architecture du projet, vous pouvez vous y retrouver facilement coté serveur si on vous a donné l’url de la page à modifier ou inversement si vous savez où est le contrôleur.
Voilà, c’était une petite présentation sur l’architecture micro-services, qui j’espère vous donnera l’envie d’en savoir plus et pourquoi pas de la mettre en place sur vos nouveaux projets (modifier l’architecture d’un projet déjà existant est souvent long, compliqué et couteux).
Bonjour,
Aujourd’hui, je veux vous parler du niveau de maturité de maturité de communication de webservices rest : hateoas.
Cet article fera volontairement des raccourcis et sera vulgarisé.
Tout d’abord, il faut faire un petit résumé rapide sur les webservices.
L’objectif d’un webservice est de permettre la communication entre deux machines sans qu’elles ne sachent quel langage de programmation chacune utilise.
Par exemple, un serveur java peut communiquer avec un serveur php sans que ça pose de problème. Le serveur qui met à disposition le webservice va dire ce qu’il attend en entrée comme format (XML pour la norme SOAP par exemple), les informations qui devront être obligatoirement renseignées, celles qui sont facultatives, etc. En sortie, il renverra un fichier, qui lui aussi qui sera normé.
Il existe deux normes de webservice : SOAP (basé sur les fichiers XML) et REST (basé sur le protocole HTTP).
L’avantage du REST est qu’il peut directement appelé par un navigateur web.
Les développeurs se sont dit : « hé, si on peut appeler les webservices REST depuis un navigateur, il y a moyen de développer une application web qui serait basé que sur des webservices REST. Et non plus des controleurs web d’un coté et webservices de l’autre. »
Et oui, avant on devait faire un controleur web qui renvoyait, par exemple, une page d’affichage de données et si un serveur distant devait également avoir accès à ces mêmes données, on devait faire un webservice qui lui renvoyait. Maintenant, on peut faire un seul et même point d’entrée : le webservice REST qui pourra renvoyer les données aussi bien au navigateur qu’à un autre serveur.
Oui, mais on doit pouvoir donner des informations sur les échanges entre les machines.
Si mon navigateur envoie des données qui ne sont pas attendues par le webservice, ce dernier doit pouvoir lui dire qu’il y a eu un problème.
C’est là qu’intervient les différents niveaux de maturité des webservices.
Dans ce niveau, le plus bas, tout se passe en POST (signifie normalement qu’on envoie des données au serveur) sur une même url et le serveur répondra toujours 200 (code pour OK), que la requête se soit bien passée ou non.
Le problème est que pour afficher des données, le POST ne sert à rien; et le code 200 renvoyé, quelque soit le vrai état de la requête coté serveur, n’est pas satisfaisant car ça peut cacher une erreur.
Avec ce niveau, on appelle toujours le serveur en POST, mais là on va enrichir l’url en lui disant par exemple quel objet on cherche à avoir.
Ex, si on veut récupérer l’utilisateur 42, l’url sera du type :
www.monsupersite.fr/user/42
Si on cherche à avoir le produit 12, l’url sera du type :
www.monsupersite.fr/product/12
Si on veut avoir tous les utilisateurs, l’url sera du type :
www.monsupersite.fr/users
Ainsi, on voit que l’url commence à « dessiner » ce qu’on fait réellement sur le site.
Là, en plus d’avoir des url différentes suivant ce qu’on fait, on demande au serveur des données d’affichage avec le mot GET, l’ajout d’un nouvel élément avec le code PUT, la modification avec POST et la suppression avec DELETE.
Le serveur en retour répondra avec un code différencié du style : 201 pour dire que la création s’est bien passée, 404 pour dire que la ressource n’a pas été trouvée, etc.
L’objectif de ce niveau est d’en plus d’avoir un échange verbeux entre les machines (niveau 2, pour rappel), permet aussi d’envoyer des liens vers d’autres webservices liés à l’action qu’on vient de faire.
Par exemple, si on veut récupérer les informations d’un utilisateur, on fera :
Appel en GET vers l’url : www.monsupersite.fr/user/42
Le serveur renvoie 200 et en plus des liens vers le webservice qui liste les produits achetés par ce même utilisateur.
Le retour est du style :
[
{
"user" : {
"id" : 42,
"name" : "toto",
"email" : "toto@monsupersite.fr",
"links" : [
{
"rel" : "self",
"href" : "http://www.monsupersite.fr/user/42"
}
],
"products" : {
"links" : [
{
"rel" : "self",
"href" : "http://www.monsupersite.fr/user/42/products"
}
]
}
}
}
]
Ainsi, en plus d’avoir les informations liées à l’utilisateur directement, nous avons aussi le lien vers le webservice qui permettra de récupérer les produits achetés par ce même utilisateur.
Il peut bien sur avoir plus d’une sous partie dans le résultat renvoyé par le serveur.
Comme il s’agit d’un degré de maturité proposé par une personne, Leonard Richardson, il ne s’agit pas d’un standard. Donc chacun peut faire ce qu’il veut.
A mon sens, l’intérêt de Hateoas est d’autant plus important si on l’utilise dans le cadre d’une application basée sur l’architecture microservices (qui sera expliqué dans le prochain article).